Mtro. Manuel García Minjares
Coordinación de Universidad Abierta Innovación Educativa y Educación a Distancia, UNAM
La evaluación es una actividad inherente a la práctica médica cotidiana; por ejemplo, el juicio de valor que encierra un diagnóstico clínico es el resultado de recabar e integrar información de diversas fuentes. De manera paralela, muchos especialistas enriquecen su labor profesional con la docencia. Esta actividad implica evaluar continuamente el aprendizaje del alumnado, una tarea que, por lo general, se realiza mediante la aplicación de exámenes.
Al momento de calificar un examen, es común que surjan interrogantes como: ¿Se explicaron correctamente los temas que se evaluaron? ¿Tienen los alumnos las bases para alcanzar los resultados esperados? Sin embargo, también es fundamental cuestionarse sobre la calidad del instrumento.
La pregunta detonadora de esta ponencia fue directa: ¿Alguna vez ha aplicado un examen que no evalúa del todo lo que pretende medir? Ante esta inquietud, muy común en el ámbito docente, por fortuna existe una manera científica de evaluar las evaluaciones, en especial aquellas de altas consecuencias. La sesión se enfocó en demostrarlo.
El proceso de elaboración de un examen de alto impacto
Antes de entrar en materia estadística, es necesario contextualizar el análisis psicométrico dentro del ciclo de vida de un examen objetivo. El proceso comienza mucho antes de redactar los reactivos (ítems) e incluye los siguientes pasos:
- Definición del constructo a evaluar y determinación del perfil de referencia
- Elaboración de una tabla de especificaciones
- Determinación de la estructura del examen
- Diseño, elaboración y revisión cualitativa de los reactivos
- Aplicación y análisis del examen
- Generación de resultados
La verdadera prueba de fuego de cualquier instrumento ocurre durante su aplicación, ya sea en una fase piloto o en la definitiva. Una vez que los sustentantes responden el examen, sigue una etapa denominada calibración. Este es el análisis estadístico del instrumento, el cual permite detectar si un reactivo está mal formulado o resulta confuso. Tras este análisis cuantitativo, se realiza una revisión cualitativa para decidir si el reactivo debe conservarse en la calificación final. Solo después de este escrutinio se integra el examen definitivo, se emiten las calificaciones y se alimenta un banco de reactivos con parámetros idóneos.
Dos enfoques para analizar reactivos
Existen dos marcos teóricos para el análisis de reactivos de opción múltiple: la Teoría Clásica de los Test (TCT) y la Teoría de Respuesta al Ítem (TRI). Esta sesión se centró en la primera.
Fundamentos de la Teoría Clásica de los Test (TCT)
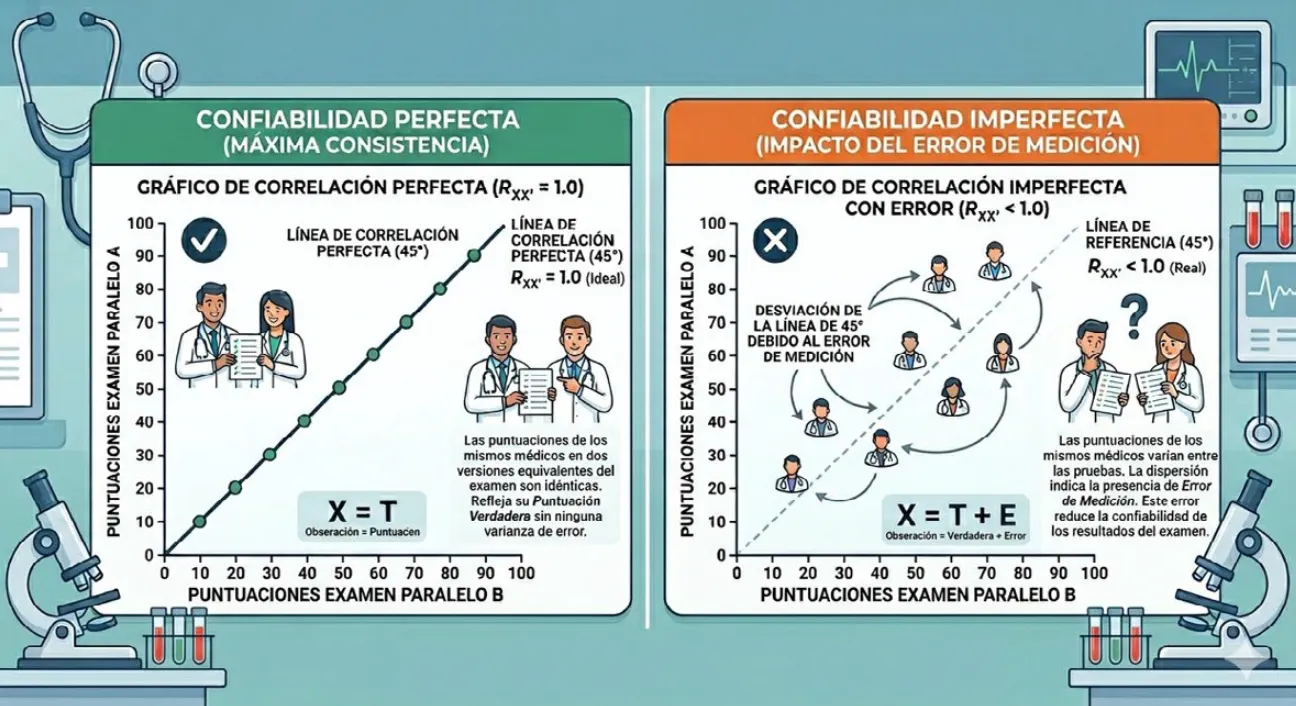
Desarrollada a principios del siglo XX a partir de los trabajos de Charles Spearman, la TCT se fundamenta en un modelo lineal sencillo compuesto por tres elementos: la calificación empírica u observada (X), la calificación verdadera (V) y el error de medición (E).
La relación matemática es la siguiente:
X = V + E
Lo interesante de este modelo es que no son observables ni la calificación verdadera ni el error; solo pueden estimarse a partir de la calificación empírica. El modelo descansa sobre tres supuestos clave:
- El error tiene un valor esperado de cero: el error de medición es una variable aleatoria cuya distribución exacta se desconoce, pero se asume que su promedio tiende a cero y que su varianza es constante en todas las mediciones. Intuitivamente, la teoría postula que, si una persona realizara el mismo examen un número infinito de veces sin que su memoria o fatiga interfirieran, el promedio de todas sus calificaciones empíricas sería su calificación verdadera.
- Independencia entre calificación y error: la calificación verdadera y el error de medición no están correlacionados. Una calificación alta no implica necesariamente un error alto, ni viceversa.
- Independencia entre aplicaciones: el error cometido al evaluar a una persona en un examen es totalmente independiente del error cometido en otra aplicación.
Para sostener este modelo, se utiliza el concepto de exámenes paralelos que son instrumentos distintos que miden exactamente lo mismo con diferentes reactivos.
Confiabilidad y error estándar de medición: parámetros globales del instrumento
La confiabilidad de un examen se define como el grado en que sus resultados son reproducibles, teóricamente se expresa como la correlación entre los puntajes de dos exámenes paralelos con poblaciones pareadas de acuerdo con su nivel de conocimientos, y que puede entenderse como el grado de coincidencia de los puntajes verdaderos respecto a los empíricos. Cuando la correlación es perfecta, es decir, igual a uno, significa que no existe error de medición. Conforme el error de medición aumenta, la confiabilidad disminuye. La forma más común de estimar la confiabilidad es mediante el coeficiente alfa de Cronbach, y se considera aceptable cuando su valor supera 0.7.
El error estándar de medición (SEM, por sus siglas en inglés) es una estimación de la variación del error desconocido en el modelo y puede calcularse una vez que se ha determinado la confiabilidad del examen mediante la siguiente relación:
SEM = σx √(1 − ρXX')
Donde σx es la desviación estándar de las puntuaciones empíricas y ρXX' es la confiabilidad.
Este valor representa la distancia promedio entre la calificación verdadera y la empírica. Se busca que este valor sea lo más pequeño posible. Debido a que el SEM y la confiabilidad se encuentran relacionados, y si se parte de que el valor mínimo deseable de este parámetro es de 0.7, entonces implica que el máximo valor de SEM permitido es de 55% de la desviación estándar de las puntuaciones empíricas.
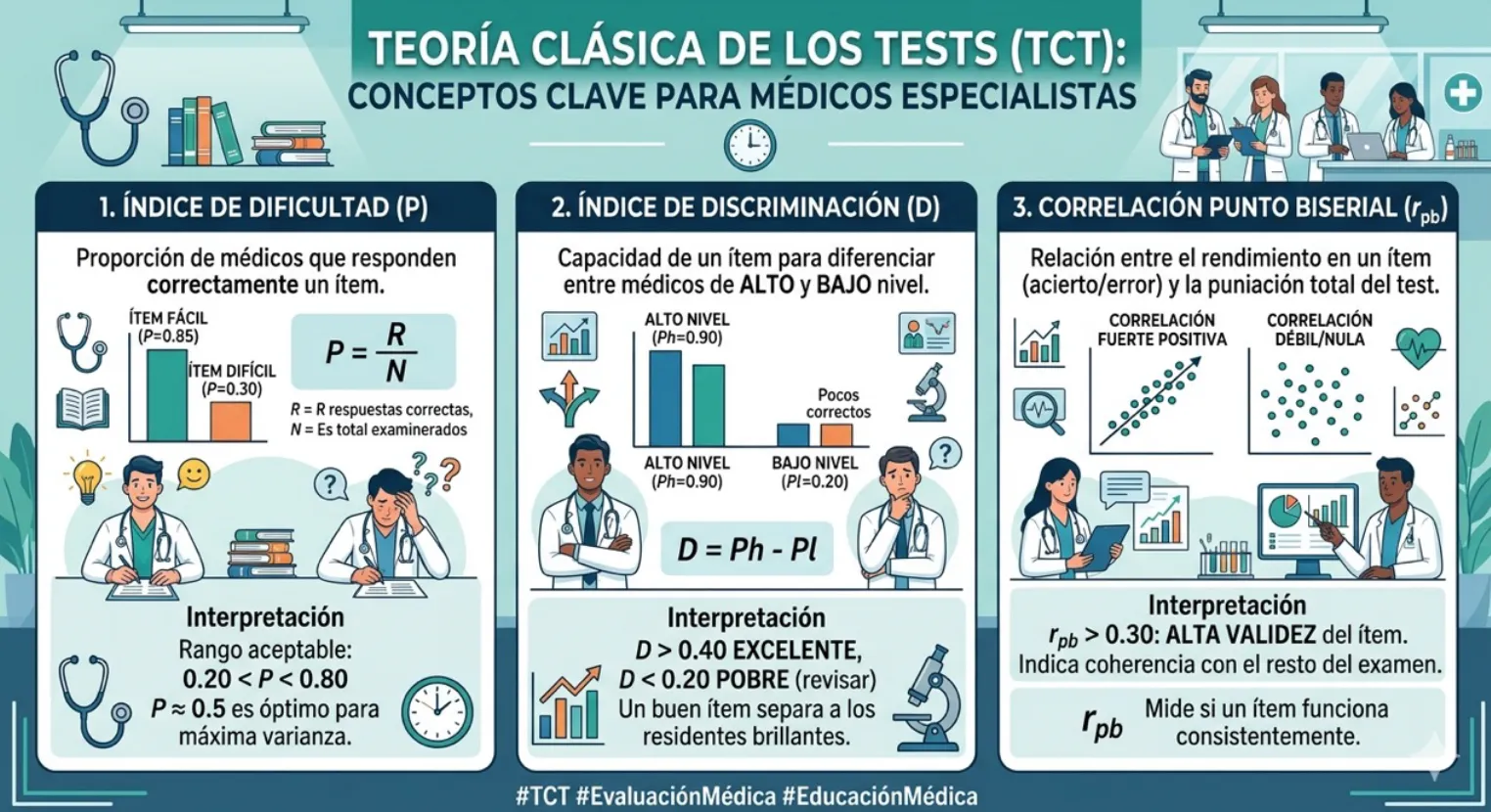
Parámetros para evaluar el funcionamiento de los reactivos
Así como se puede evaluar el comportamiento de un examen de manera global, también es posible realizar una evaluación a detalle por reactivo. Los tres parámetros a revisar de los reactivos de opción múltiple son los siguientes:
Dificultad. Es la proporción de aplicantes que responde correctamente el reactivo. Su valor oscila entre 0 y 1, conforme este valor se acerca a 0 significa que el reactivo es cada vez más difícil, por otro lado, a medida que la dificultad se acerque a 1 implica que es más fácil. En un examen de altas consecuencias se sugiere que este parámetro se ubique entre 0.2 y 0.8. Si se considera que responder correctamente es elegir la respuesta correcta, entonces significa que los distractores debieron ser seleccionados entre la población que falla, por lo que al revisarlos todos deben haber sido elegidos. Como sugerencia debe considerarse que un distractor es descartable si lo elige menos de 5% de los aplicantes.
Discriminación. Es la capacidad del reactivo para distinguir entre los sustentantes que dominan el contenido y los que no. Se calcula como la diferencia entre la dificultad observada en el grupo de alto rendimiento, o el 25% más alto y la observada en el grupo de menor puntaje. El valor mínimo deseable para considerar que un reactivo discrimina adecuadamente es de 0.2. En el caso de los distractores, éstos deben ser negativos, lo que significa que los eligen más los sustentantes de menor desempeño.
Correlación punto biserial. Relación se encuentra entre un reactivo y el desempeño general del examen. Quien responde correctamente, ¿tiende a tener un buen desempeño? Una correlación positiva lo confirma. El valor mínimo deseable es de 0.15, aunque valores iguales o superiores a 0.2 se consideran buenos indicadores de funcionamiento. En el caso de los distractores, su correlación punto biserial debe ser negativa, ya que se interpretaría que quienes no eligen la opción correcta tienden a tener los puntajes más bajos.
Un caso práctico
Para ilustrar estos conceptos, el ponente analizó un examen final de un curso de vacunación aplicado a 2,011 alumnos. El instrumento constaba de 50 reactivos divididos en seis áreas temáticas.
Resultados globales. El promedio de aciertos fue de 33 a 34, con una desviación estándar de 7.5. La dificultad media fue de 0.66 (un examen relativamente fácil), y la correlación punto biserial media fue de 0.31 (buena alineación de los reactivos con el puntaje total).
Confiabilidad. El Alfa de Cronbach alcanzó 0.85, un nivel excelente de reproducibilidad. El SEM fue de 3 aciertos (40% de la desviación estándar), aportando fuerte evidencia de validez.
Comportamiento de los reactivos. Aunque el examen fue fácil para el grupo de alto rendimiento (dificultad >0.8), mantuvo una dificultad intermedia para el grupo de bajo rendimiento. Esto demostró una buena capacidad de discriminación global. No obstante, el análisis detectó dos reactivos con baja discriminación y una correlación anómala, los cuales requerían revisión cualitativa por parte del comité de expertos para entender por qué estaban confundiendo a los alumnos de alto rendimiento.
Limitaciones de la Teoría Clásica de los Test
Si bien la TCT es una herramienta útil y comprensible, presenta ciertas limitaciones.
- Dependencia del tamaño de la muestra: los parámetros, como la dificultad, son inestables si se calculan con pocos casos. El comportamiento de un reactivo suele ser errático hasta que se alcanza un tamaño considerable, digamos alrededor de 50 observaciones.
- Dependencia circular: en la TCT, la dificultad del examen depende del nivel del grupo evaluado, y la habilidad estimada del grupo depende de la dificultad del examen.
- Asume un error constante: la TCT ignora que el error de medición puede variar dependiendo del nivel de habilidad de cada persona frente a reactivos específicos.
Observaciones finales
La elaboración de un examen objetivo de altas consecuencias es un proceso complejo que exige tiempo, rigor y equipos especializados.
Es crucial entender que el análisis psicométrico proporciona los elementos para revisar con detenimiento ciertos reactivos para determinar su permanencia. Los valores de los parámetros deben complementarse siempre con una revisión cualitativa mediante el diálogo y consenso de expertos, quienes tienen la última palabra sobre la inclusión o descarte de un reactivo.
Finalmente, a medida que las instituciones maduran en sus procesos de evaluación, se recomienda utilizar software especializado para complementar los análisis de la TCT con la Teoría de Respuesta al Ítem (TRI), un modelo que ofrece mayor potencia analítica y supera varias de las limitaciones del enfoque clásico.